

- Published on
Why LLMs mess up the simple things
- Authors
- Name
- Nathan Brake
- @njbrake



Bing Image Creator "The phrase "Tokenization is the worst", split into 10 different chunks""
A Confusing ChatGPT response
In the below prompt and response, I ask ChatGPT to tell me whether two of the exact same word are the same. I copy pasted the word twice, so they are definitely spelled exactly the same. ChatGPT answers correclty, but it looks like ChatGPT made an obvious mistake when explaining the answer: the two words are exactly the same, but ChatGPT is saying that one is capitalized while the other isn't. There is no difference in capitalization between the two words!

But now look closer: see that single space I added before the second typing of "supercalifragilisticexpialidocious" in my question? That little space is the reason that ChatGPT is confused. In this blog I'll explain why this added space is causing the issue, and how it should effect your approach in interactions with LLMs like ChatGPT.
Tokenization in Large Language Models: A Deep Dive with Andrej Karpathy
I was really excited to see that software engineer Andrej Karpathy (well known in the AI/ML community) had left OpenAI and announced his intention to put more effort into teaching. His youtube channel lectures on the GPT architecture and Large Language Models (LLMs) are super helpful in understanding the internals of LLMs.
Last week he released his newest lecture, all about tokenization. I was disappointed at first because in the past I've found the topic of tokenization to be sooo boring. It's the process of turning text into integers that can be processed by a LLM, and it's not as exciting to me as model architecture research or training. However, after finally getting around to watching the video this week, I'm changing my tune. Andrej's explanation ignited my interest in tokenization and I'm now convinced that it's a critical piece of LLM architecture that shouldn't be overlooked. Understanding how tokenization works can help to explain strange LLM functionality, issues, and vulnerabilities. In this blog post, I want to specifically focus on one topic that Andrej addresses. Andrej's lecture on tokenization is here. It's 2 hours long but it's packed full of interesting information and well worth the watch for anyone working to build AI.

What is Tokenization
This post assumes that you are already familiar with generally what tokenization is. This post by huggingface is a good explanation. At a high level, tokenization is the process of turning text into a list of numbers which correspond to indexes of vectors in a LLM vocabulary embedding to represent pieces of the text that can be processed by the LLM. ChatGPT (and many modern LLMs) use what's called Byte-Pair Encoding (BPE) tokenization. BPE tokenization is a method of tokenization that is based on the frequency of character sequences in a corpus of text. It's a method that is particularly good at handling out-of-vocabulary words, and you can read about it on wikipedia. BPE tokenization uses the " " (space) character to help differentiate a word segment that is the start of the word vs a word segment that is internal to a word.
Why ChatGPT mentioned something about capitalization
The website https://tiktokenizer.vercel.app/ allows for visualization of how BPE tokenization is working in GPT-3.5 (ChatGPT). In the below image, each different color string of text in the right window indicates the characters that are being tokenized together.
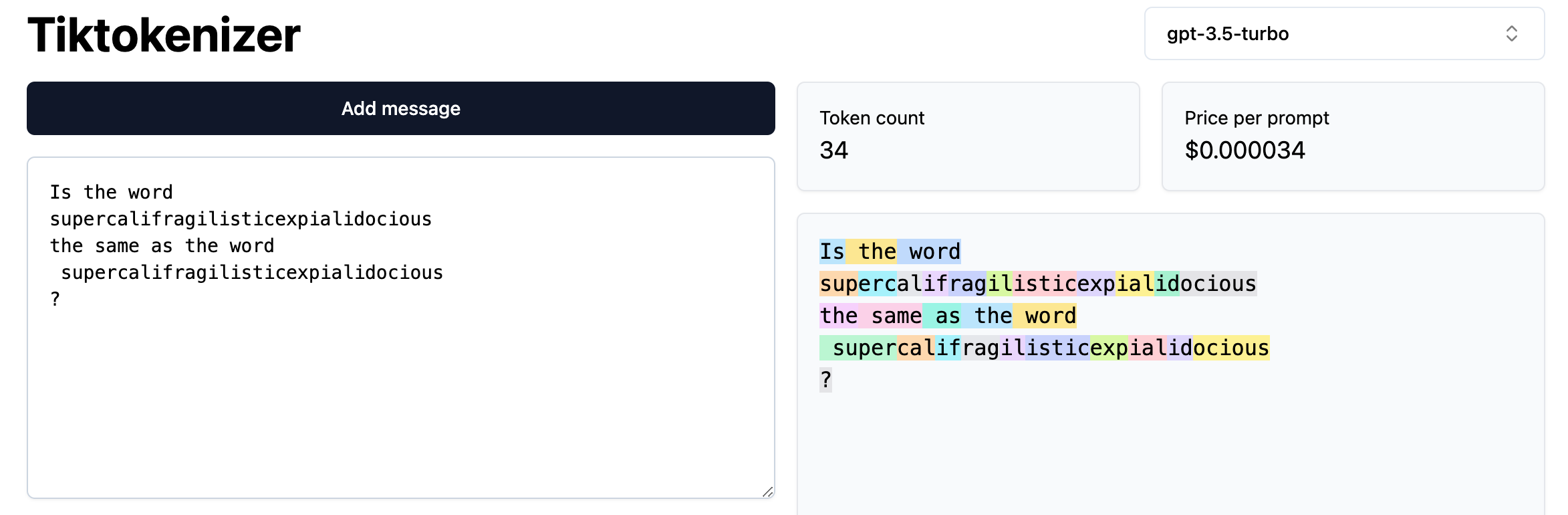
From this image you can now see that the tokenizer split the first few tokens of "supercalifragilisticexpialidocious" into ["sup", "erc", "al"], and the second "supercalifragilisticexpialidocious" into [" super", "cal"].
This is why ChatGPT gets confused, because internally, the LLM is actually receiving two different sequences of tokens. Due to its training, ChatGPT learned that the two sequences have the same content, but it's not able to identify that they are the exactly the same. In this case, it guesses that the reason the two token sequences aren't exacly the same was due to capitalization, when in reality the difference we due to the insertion of the " " character.
Conclusion
In this example the issue was caused by an added space character, but you can see similar issues if you add capitalization in random parts of a sentence, or add spaces or typos in places where the LLM may not expect them to be. If you are chatting with an LLM, pay careful attention to where you insert spaces or newline characters in your text. Even though as a human it's easy to glance over small errors, those differences can make an outsized impact on the quality of the LLM's response.