

- Published on
Langchain: An Overview of my Experience with the LLM Framework
- Authors
- Name
- Nathan Brake
- @njbrake



Bing Image Creator The phrase "A colorful futuristic parrot who is looking at a computer screen and getting dizzy"
When it comes to building LLM applications like chatbots, question answering tools, and information retrieval applications, I’ve found no framework to be more publicized than Langchain. If you Google anything related to “how to build an LLM that does x” almost invariably the demo blog or video you find uses Langchain.
With this knowledge, I turned to langchain when it came time to build an application that could provide structured answers to questions about a group of documents. There was only one problem.... err sorry no there were many problems: Langchain turned out to be noticeably more confusing once trying to expand beyond the basic use cases.
Unusable Langchain Hosted Chatbot
The most jarring first interaction with Langchain was with the assistant chatbot hosted on their site. The chatbot was designed to help explain the langchain documentation, but when you ask it questions (even ones that they suggest you ask), it often fails to provide a response.
I think of this like buying a car: If I go to a dealership and the car they want me to take for a test drive has a dead battery, I'm going to be less motivated to purchase a car from them. See for example the below screenshot where I ask the langchain chatbot a question (you can see it as a grayed out prompt in the chat window). Even though this was the question that that they were explicitly suggesting I ask, the chatbot doesn't respond correctly.
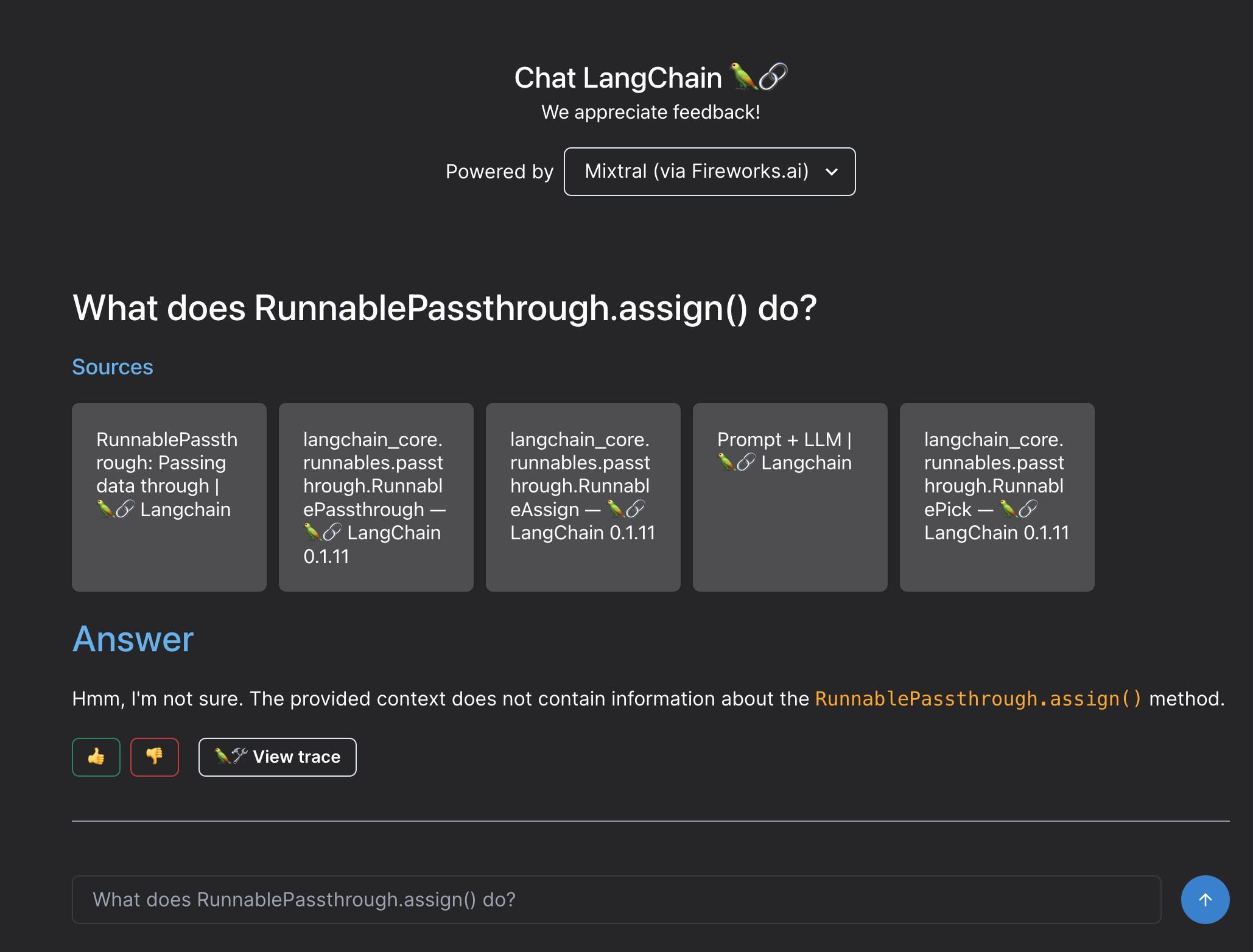
It's not a confidence boost to be trying to use langchain when the langchain provided chatbot doesn't even work.
Unclear Documentation
A software library can be as powerful as it wants, but if the documentation is unclear, it’s not going to be very useful. This is the case with Langchain. In the pursuit of keeping up to date with all of the latest advancements, the documentation (in my opinion) has suffered. Usually, my issue with libraries is that they don’t have enough documentation, but with Langchain, it’s the opposite. There’s so much documentation that it’s hard to find what you’re looking for.
When you go to documentation for a library, normally there is a single quickstart page that shows you how to get up and running. This is not the case with Langchain: they have pages titled "quickstart" for multiple parts of langchain.
There's the main quickstart: https://python.langchain.com/docs/get_started/quickstart
There's the model i/o quickstart: https://python.langchain.com/docs/modules/model_io/quick_start
There's the agents quickstart: https://python.langchain.com/docs/modules/agents/quick_start
All of the quickstarts are similar and contain examples of loading and invoking LLMs, so it's easy to confuse which quick start you're looking at when you are browsing the page.
Chat vs Non-Chat LLMs and PromptTemplates
One of the first points of confusion I had was around LLM vs ChatLLM and ChatPrompt vs Prompt classes. I was following The Quickstart to get up an running with a local LLM provided through Ollama.
In the quickstart they explain that you should load the llama LLM like so:
from langchain_community.llms import Ollama
llm = Ollama(model="llama2")
and then use a prompt template like so
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
What's immediately confusing is that we are using a ChatPromptTemplate, but not a Chat model. Langchain has a ChatOllama class, so why aren't we using that? What's the impact of mismatching a LLM with a ChatPromptTemplate, or a ChatLLM with a PromptTemplate? It's unclear.
To add to the confusion, if you call .invoke() on a LLM, it returns a string, but if you call .invoke() on a chat model, then it returns an AIMessage object.
Why is SystemPrompt and Prompt abstracted but not context?
The next confusing part that I encountered in the quickstart was the instruction about how to insert the context. Although there is a specific parameter available for specifying the system prompt, there is no parameter for specifying the context (which is what gets inserted as a part of the retrieval augmented generation (RAG) technique).
Here's how the quickstart instructs us to use the context:
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
But why do we specify context in this way: do we have to change this formatting based on what model we're using? I think so, but it's not clear. If the goal of langchain is to abstract away all of the model specific settings, this seems like an issue. RAG is such a common use case, why is the from_template() function being overloaded with the insertion of the context in such a strange way? It's not clear.
Debugging Difficulty
The biggest issue I had that was eventually the dealbreaker was the difficulty in debugging. When I'm doing "prompt engineering" with a new model, one of the first things I like to do is look at exactly what text is being fed into the LLM. As I mentioned in my blog about tokenization, little differences in how the text is sent to an LLM can make a huge difference in the output quality. However, for the life of me I couldn't find out how to print the exact text that gets sent to the LLM: A common format for sending text to an LLM might look like:
<<SYS>>
This is where the system message goes
<</SYS>>
[INST]
This is where all the context and prompt goes
[\INST]
But the problem is that I couldn't figure out how to print this exact string, the best it would give me was the context (pulled using RAG) and my prompt combined into a single string. Without being able to view the final formatting, how do I debug this thing? Maybe there's a way to do it, but it wasn't clearly documented.
Langchain publicizes and promotes LangSmith as a debugging tool. Langsmith is a service hosted by Langchain that allows you to test your prompts and see the output of the LLM. However, one of the reasons that I am using a locally hosted LLM (through Ollama) was so that I don't need a network connection to develop the system. If I need to connect to the Langsmith website in order to gain access to additional debugging tools, that's not compatible with doing local development.
Miscellaneous Issues
There were a variety of other issues I hit as well:
- Markdown parser doesn't support MDX format
- Passing the system prompt into Ollama(system="talk like a pirate in your response") doesn't seem to do anything with no indication about why
- Using PyPDF parser to extract text from a PDF file doesn't let you split into smaller chunks than a full page, and there was no documentation about how to do this. I tried adding a custom textsplitter into the
.load_and_split()function, but it didn't do anything, with no indication about why not. They provide about 5 different options to use for PDF parsers, but no documentation about what the differences are between them and why you would choose one over the other. - Agents are called with the
.run()command while LLMs are called with the.invoke()command. Why the difference? It's probably documented somewhere in the docs but it's not clear. It also appears tha maybe some integrations or legacy code is using.run()to invoke the LLM, like the HugeGraphQAChain example
Conclusion
I really wanted to like langchain. It appeared to be commonly used and support plenty of different models and RAG loading interfaces. However, my experience with langchain fell apart soon after trying to develop applications that deviated from the most basic use cases. It appears that langchain was initially designed for GPT-3.5/4 support, and although they work to support other LLMs and LLM frameworks, I'll need to wait for some updates to langchain before I try again. I really hope the library can be improved. In theory, it's a great idea to have a single library that can support so many different LLMs, but in my opinion, it's not there yet.